At my day job I’m really the only person that knows how to write WordPress plugins, so when I write one it’s usually sand-boxed on my machine where nobody can touch it. However, in a side endeavor I’m part of we have a team of 3 people developing on one plugin. As I’m the most experienced plugin developer amongst our team, I was tasked with coming up with a development style and plugin architecture that would work for us.
Development Style
Everyone will be running a local copy of WordPress and making their changes to the plugin locally. The plugin itself will be under version control using Git, and developers will push/pull changes from either a self-hosted Git server or Git Hub. Database schema will be tracked in a file called schema.sql. When someone makes a change to the schema, it goes into that file at the bottom with a comment about why the schema changed. We’ll being jQuery as our Javascript framework of choice, and we’ll be writing all of our Javascript in CoffeeScript (see my previous entries).
Plugin Architecture
The more difficult aspect of developing this plugin as a team is the sheer size of the plugin. Realistically this could probably be split into about 6 different plugins by functionality, but we want to keep everything together in one tidy package. To illustrate the architecture, I made a quick drawing.
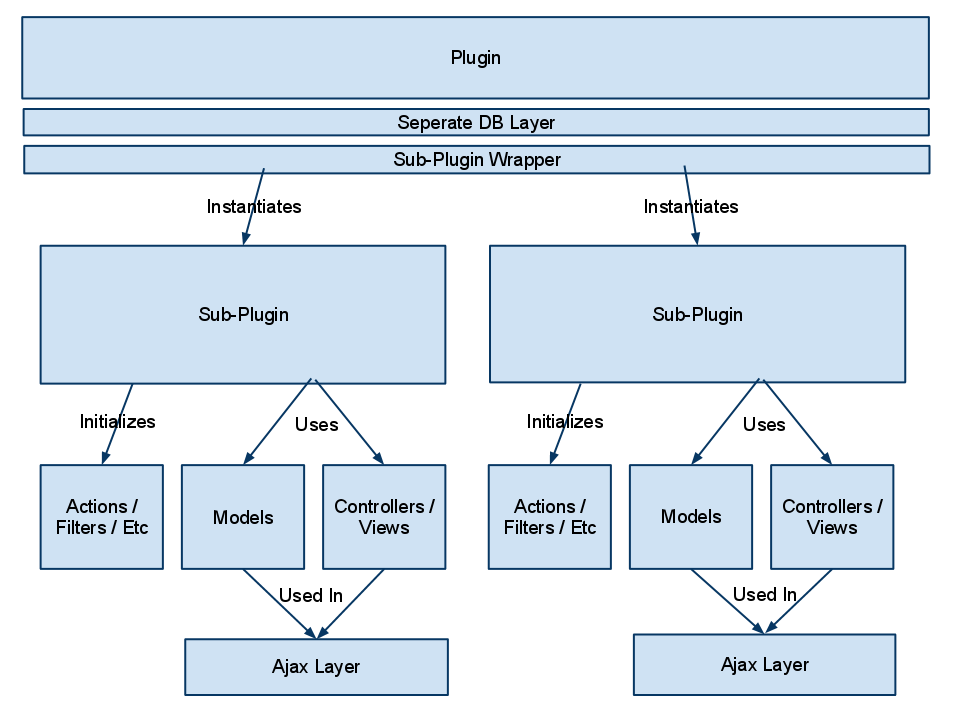
The first layer of the plugin is essentially a wrapper. It initializes the ORM that we are using to access the database (we are using a separate database for this plugin’s data), and includes the wrapper class. The wrapper class is where developers drop their sub-plugin include file and instantiate it’s main object. For instance, for each sub plugin there will probably be two classes instantiated in the wrapper. One being admin related functionality, and the other being for front-end display functionality. My thinking with this architecture was that we could all work on separate sub-plugins without crossing paths too frequently. This also allows us to separate the different functionality areas of the plugin in a logical manner. The other benefit to architecting the plugin like this is that it will be very easy to port to a different architecture in the future. I’m well aware that WordPress probably isn’t the best tool for the job, but it is the best tool for the team with the deadline that we have.
Thoughts
While thinking about WordPress Plugin Architecture, I cruised the source code of a lot of plugins and it seems that everyone goes about it in a different way. If you’ve ever developed a large-scale plugin with a team, how did you go about doing it? Did you run in to any problems that you didn’t foresee at the beginning of the process?